Lower Lock % and Number of Slow Queries
Gauges tracks several websites. Some get a lot of traffic and others don’t. The sites that get a lot of traffic tend to stay hot and sit in RAM. The sites that get little traffic, eventually get pushed out of RAM.
This is why for Gauges, we can have 1GB of RAM on the server and over 14GB of indexes, yet Mongo hums along. Even better yet, of that 1GB of RAM, we only use around 175MB.
RAM, What Needs to Fit There
You have probably heard that MongoDB recommends keeping all data in RAM if you can. If not, they suggest at least keeping your indexes in RAM.
What I haven’t heard people say as much, is that you really just need to keep your active data or indexes in RAM. For stats, the active data is the current day or week, which is a much smaller data set than all of the data for all time.
Write Heavy
The other interesting thing about Gauges is that we are extremely write heavy, as you would expect for a stats app. Requests due to the tracking script loading on a website are over 95% of all requests to Gauges.
Some of these track requests are for sites that rarely get hit, of which, the data that needs to be updated has been pushed out of RAM and is just sitting on disk.
Global Lock is Global
As you probably know, MongoDB has a global lock. The longer your writes take, the higher your lock percentage is. Updating documents that are in RAM is super fast.
Updating documents that have been pushed to disk, first have to be read from disk, stored in memory, updated, then written back to disk. This operation is slow and happens while inside the lock.
Updating a lot of random documents that rarely get updated and have been pushed out of RAM can lead to slow writes and a high lock percentage.
More Reads Make For Faster Writes
The trick to lowering your lock percentage and thus having faster updates is to query the document you are going to update, before you perform the update. Querying before doing an upsert might seem counter intuitive at first glance, but it makes sense when you think about it.
The read ensures that whatever document you are going to update is in RAM. This means the update, which will happen immediately after the read, always updates the document in RAM, which is super fast. I think of it as warming the database for the document you are about to update.
Based on these graphs, I am pretty sure you will be able to tell that it was January 27th in the evening when I started pushing the query before update changes out:
Lock Percentage
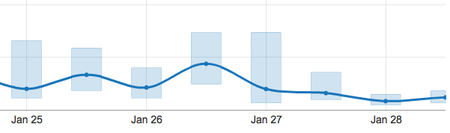
Slow Queries
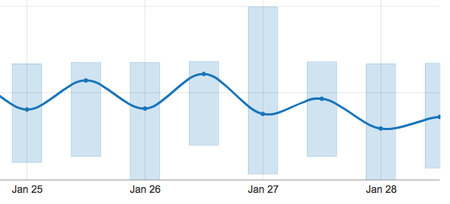
Obviously, this dramatically increased the number of queries that we performed, but it has added less than a few milliseconds to our application response time and the database is more happy.
Number of Reads/Writes
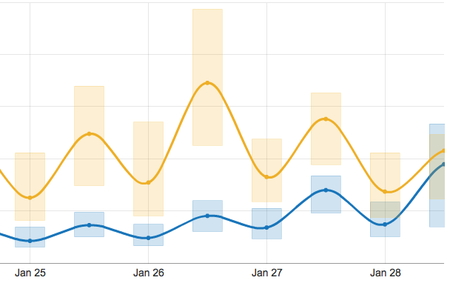
Reads are blue and writes are yellow.
Granted my explanation above is simplistic, but you get the gist. Query before update ensures that the updated document is in RAM and that the update is fast. I remember reading it somewhere and I kept thinking I should try it. Finally, I did, and it definitely helped.
Note: At the time of this writing, we are running MongoDB 1.8.×. MongoDB 2.x has significant improvements with regards to locking and pulling documents from disk, not to say that this technique won’t still help.
If you want to learn more about how we use MongoDB for Gauges, you can check out my MongoDB for Analytics presentation.
7 Comments
Jan 30, 2012
“MongoDB 1.2.x has significant improvements…”
Did you mean MongoDB 2.1.x?
Jan 30, 2012
@Srdjan: Ah, yep. Correcting…
Jan 30, 2012
Hey John, what are you using to generate the graphs?
Jan 30, 2012
@Michael Guterl: Those are screenshots from scoutapp.com.
Jan 30, 2012
@Michael Guterl: Those are screenshots from scoutapp.com.
Jan 31, 2012
Not sure if we heard about this technique from the same place, but I first heard about using it with MongoB during Kenny Gorman’s presentation at MongoSF 2011. The same idea has been used in the MySQL world to speed up replication slaves. You read ahead in the replication log, transform modification SQL to a SELECT and then run the SELECT.
Jan 31, 2012
@Robert Stewart: I wasn’t at MongoSF, but I may have saw it in a slide deck. Thanks for the links!
Thoughts? Do Tell...